
Phishing is still one of the most prominent ways of how cyber adversaries monetize their actions. Generally, phishing tries to accomplish two primary goals:
- Gain initial access to network — Adversary sends spear phishing e-mail with a well-crafted pretext and malicious attachment. Adversary then waits until the victim opens the attachment and connects to the C2 server. The attachment is usually one of Office file formats in combination with VBScript/WScript/Powershell and has pretty high success in evading anti-virus (when done correctly).
- Steal credentials for online services — Adversary clones some high-value website (usually login form of some web services) and convince the user to enter her credentials. Adversary then gathers the credentials and uses it to further (malicious) actions. The cloned website is delivered to the victim using different channels. Delivery of such website (with pretext) to the user depends on the adversary "audience". Generally, e-mail is a prominent delivery channel for this type of phishing as well. The attachment is not present this time. However, the pretext is crafted in a way that it contains URL to the malicious domain. Other channels include Whatsapp, Facebook Messenger, etc.
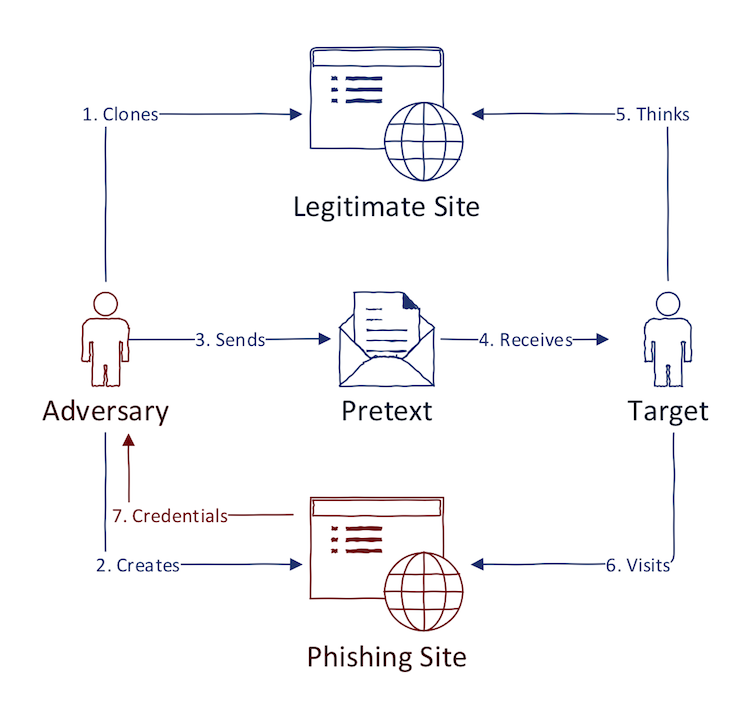
When dealing with incident response, the general workflow in analyzing phishing is in most cases reactive. In other words, incident responders wait until some tech-savvy employee/customer reports the suspicious phishing site, suspicious e-mail, or start seeing suspicious traffic in SIEM. At that time, it is likely that other employees have already been compromised.
In this post, I want to focus on the latter category and describe, how you can proactively find domains that try to mimic the websites of some particular organization (read yours). I will focus on:
- Websites mimicking intranet sites to get valid internal network credentials.
- Websites mimicking product sites to get valid credentials from your customers. These can the result of brand damage since the phishing site is associated with your brand.
By proactively detecting these sites, you can be prepared to face phishing waves inside your organization and notify your customers about malicious actions hopefully before they happen.
Please note that if you want to get some results from these techniques, you should implement continuous processes regarding automation instead then one-time search. By no means you should expect perfect process for this problem - instead, we are trying to use heuristics to find a significant amount of badness without least amount of false positives.
I will dedicate the whole post for explaining details of attachment-based spear phishing, including macro creation and some Powershell tricks.
Domains
Firstly, let's look at the general scheme of finding such domains/websites. Since there are countless websites created every day, it would be pretty hard to check them all. We need to limit the scope, somehow. Usually, an adversary creates a new domain that at least look somehow legitimate:
- Typosquatting domain — Typosquatting is a technique of registering domain names which look similar to some legitimate domain name. For instance, given google.com, one example of typosquatting domain might be g00gle.com
(notice the "zero" instead of "o"). Such domain name appears identical to the original one. There is a large list of typosquatting techniques. - Doppelganger domain — A doppelganger domain is similar to typosquatting domain. It is a domain which is missing "." (dot) in a domain name. For example, an instance of Doppelganger domain for mail.google.com is mailgoogle.com (notice the missing dot). When the content on these domain matches branding and content of the original website, users are not able to tell the difference and are more likely to be tricked by an attacker (e.g., for credential harvesting or financial fraud).
- Domain with keyword present — The new trend in phishing domains is, that adversaries create long domain names with gibberish, but include the keyword of targeted brand inside the domain name. Because of keyword and (almost always) SSL certificate present, users believe that this is indeed a legitimate site. This should by no means be considered as a rule. There are certainly domain names that clone some brand but doesn't include any such keyword in FQDN.
From my own experience, the last category is the most prominent. One of the reasons is that many typosquatted domains for popular brands are already registered. An adversary needs to be more creative and look for typosquatting domains which are easily spotted as somehow suspicious by a majority of users.
On the other hand, a long domain name with brand name present as a keyword is "less" suspicious that somehow weirdly typo-squatted domain. Keep in mind that these are my opinions about this problem.
Finding typosquatting
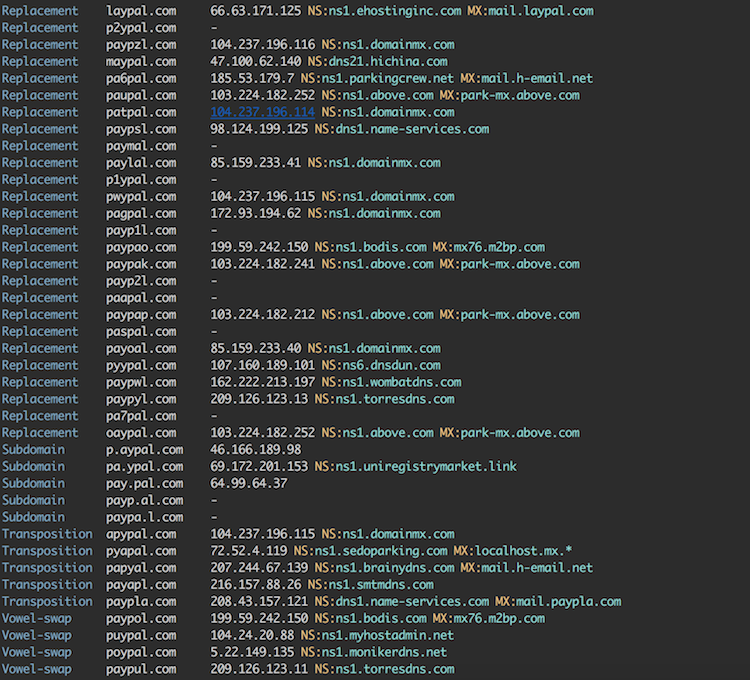
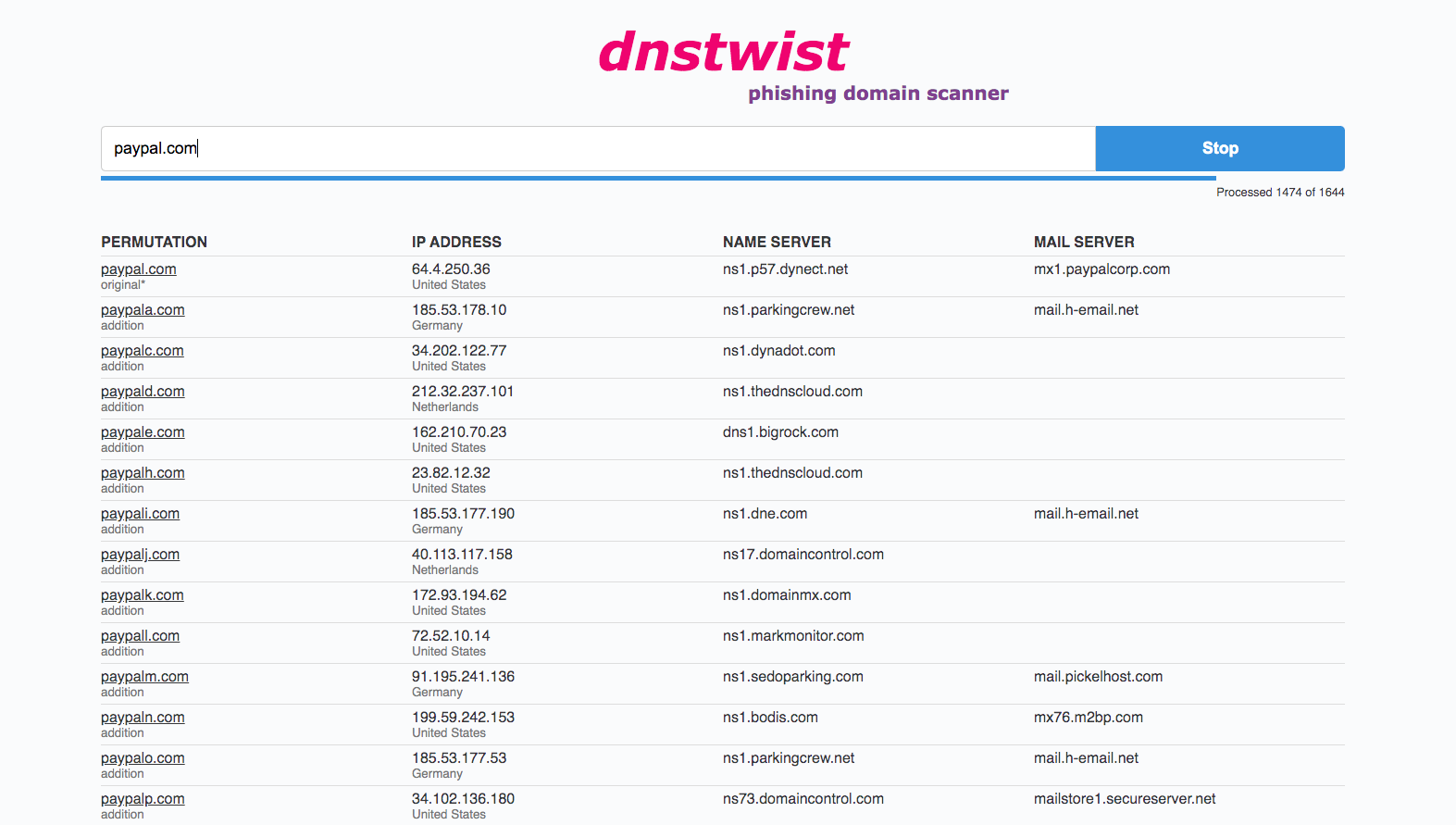
There is probably just one tool you need for detecting typosquatting: dnstwist. It is a Python package that will enumerate all typosquatting possibilities and present you with a nice report. The list of domains can be then fed to EyeWitness to see, whether some domain is hosting something potentially malicious.
Excerpt from dnstwist running on paypal.com:
Alternatively, there are online services like dnstwist.it which do the similar thing directly in your browser.
Finding Long Domains with the Keyword
Before going forward, I recommend reading Censys Guide that I wrote before.
The technique in this section is possible because of two things that emerged in recent years:
- Free CA's such as Let's Encrypt
- Certificate Transparency
The basic premise is this: Since the TLS/SSL certificate is now free to obtain, adversaries in most cases issue one for the malicious domain. "Secure" badge in URL bar makes things more legitimate.
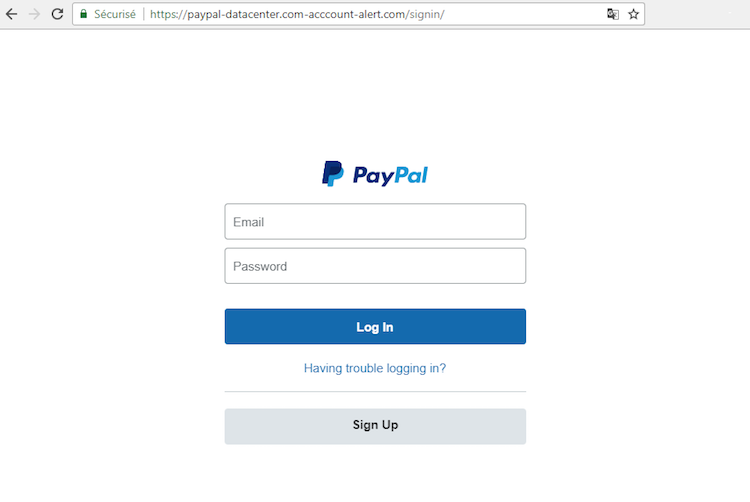
(Picture taken shamelessly from https://github.com/x0rz/phishing_catcher)
How can we leverage this fact?
Certificate Transparency (CT) is a project that collects the majority of certificates that were issued and provided this data to the public. By parsing CT logs, we can easily extract domain names (from Subject / SAN fields) and make a simple syntactic comparison of keywords inside these domain names.
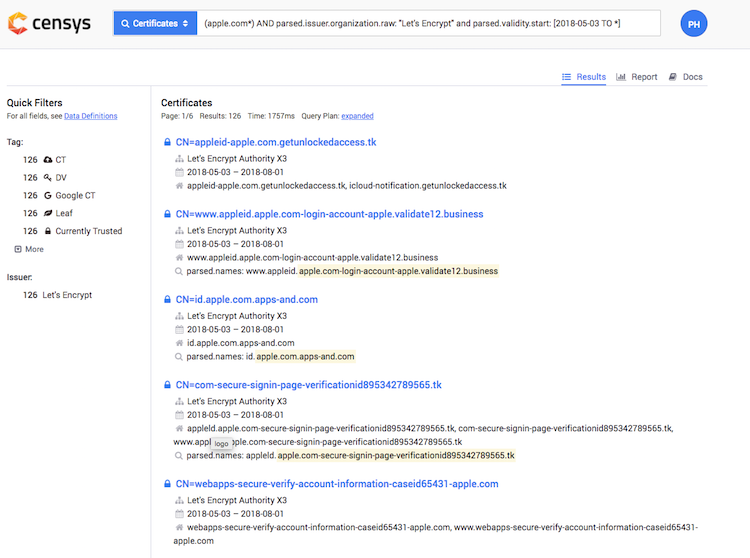
Firstly, we need to get access to Certificate Transparency logs. There are numerous services offering this, including certdb, and crt.sh. I don't use either of these two because they don't offer advanced query options. I recommend you start using Censys for querying CT logs.
Secondly, we need to gather a list of potential keywords we want to search. The most common keyword would be the full domain name of some company/service (e.g., apple.com). You shouldn't stop here but look for variations like striping TLD (apple) or querying domain names. Beware that depending on the keyword; the result set might provide a couple of false positives which you would need to sort manually at first. I also like to filter based on particular CA (mainly Let's Encrypt) but only in cases where the result set is too big. The example query to find phishing domain for apple.com would then be:
(apple.com*) AND parsed.issuer.organization.raw:"Let's Encrypt"
you can also limit the results by specifying issue date range like so:
parsed.validity.start: [2018-07-09 TO *]
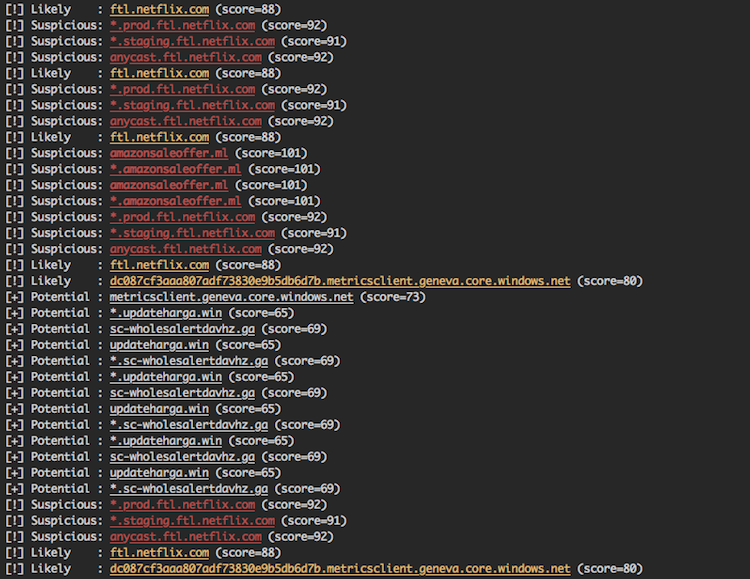
An alternative to using Censys as the primary source of CT data, you can leverage a fantastic project called CertStream. CertStream provides a real-time stream of newly generated certificates which you can use to detect specified keywords in (near) real-time. In fact, there is a project called phishing_catcher that does just like that. The major downside of this approach from my perspective is a lot of unnecessary work when you are interested in only one brand. You need to run CertStream regularly whereas Censys can be queried anytime with more advanced query options.
Screenshot from phishing_catcher:
There is also an option of creating your own certificates database using projects like Axeman.
Lastly, I want to point out why certificates are ideal for finding such domains. Long domains usually contain multiple levels of subdomains. One of the alternative ideas is to gather a list of newly registered domains for some TLDs (Whoxy provides such service) and check the keywords in these domains. The problem is that these domains are second-level domains - you need to perform subdomain enumeration first to discover all potentially malicious domains. Another problem is, that since such domain names contain a lot of gibberish, subdomain enumeration techniques are likely to fail (unless using CT sources).
Putting It Together
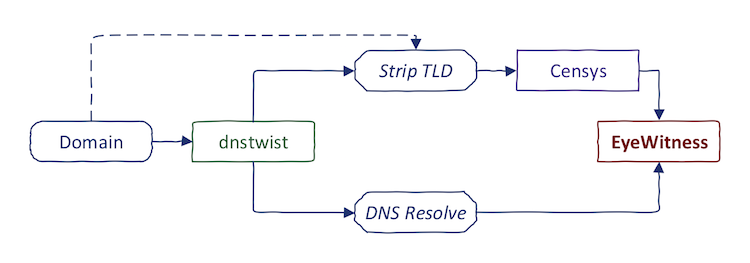
As always, I would like to automate this boring process. It is sometimes useful to combine both techniques:
- Run dnstwist on some domain
- Resolve the typosquatting domains
- Strip TLD and find them in Censys
High-level, this is the process that I follow (dotted line represents alternative approach):
Until next time!

