
You are probably shaking your head that this is another post about subdomain enumeration. I have written about it in the past, and so did much other security folks. But things have changed, and I noticed that the results I was getting were not optimal. Don't get me wrong; I inevitably got better results than most people. But there was a room for improvement. After some heavy testing, I had improved my subdomain enumeration game significantly. In this post, I want to share (some of) my thoughts about how to do subdomain enumeration.
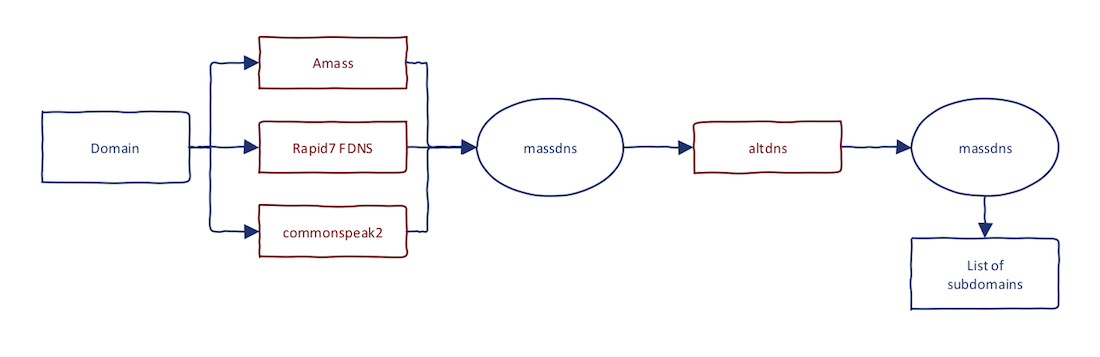
Firstly, I am all about efficiency. I want to have the best results as soon as possible. I have glued together the best tools "on the market" to come up with an efficient solution that works. If you remember from the past, I want to have continuous reconnaissance process rather than one-time-shots. These are the tools/sources for it:
- Amass
- Rapid7 Forward DNS dataset
- commonspeak2 wordlist
- massdns
- altdns (optional)
This is the combination that brings the best results for the majority of the targets I have encountered. Now, let's bring the full process:
- Use
amassto gather passive data - Retrieve subdomains from Rapid7 FDNS
- Generate possibilities from
commonspeak2 - Run
massdnson input from step #1-#3 - Run
altdnson the result set - Run
massdnson input from step #5
Step #5 and #6 are optional and take most of the time. If you don't run it, you will still get great results.
Amass
I've said it hundreds of times; amass is my goto tool for primary subdomain enumeration. Forget Sublist3r and aquatone. Subfinder is a good alternative to amass, but I have two problems with it:
- It does not have that many sources as amass
- It does things too "nicely". In other words, you require API keys for many services.
Why did I mention to use amass to get passive data? The built-in DNS resolver is just too slow. Amass should provide data from various sources; we have better tools for DNS resolution. (I have spoken about it with the amass author. The amass resolution capabilities might be improved in the future).
To retrieve a passive data using amass, simply run:
amass enum --passive -d <DOMAIN>
Subdomains from Rapid7 FDNS
Nothing surprising here. FDNS dataset is just a great way to enhance the results that amass brings. You can now use AWS Athena to query the FDNS.
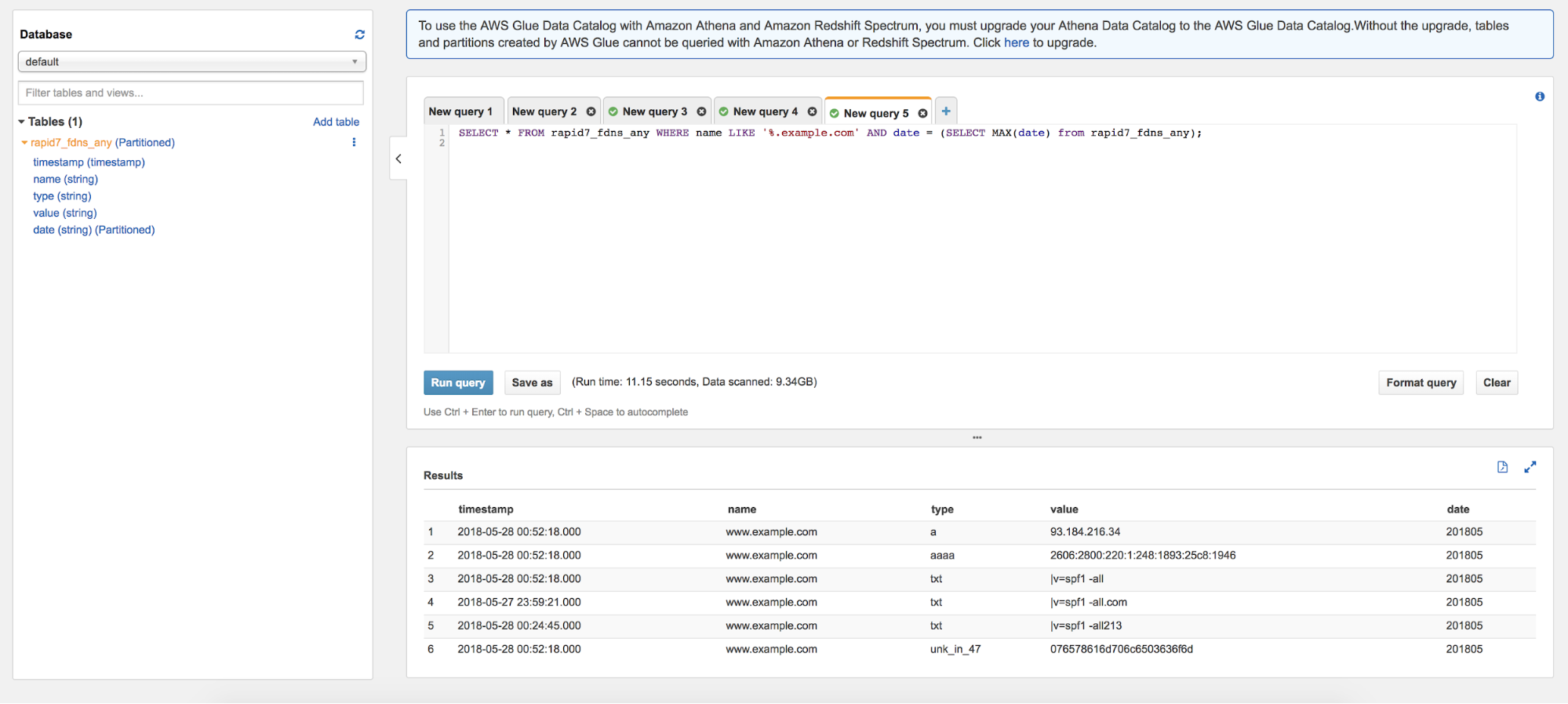
(Source: blog.rapid7.com)
Indeed, you don't need to use AWS to retrieve the subdomains, it is just much more convenient. You can definitely parse it on your own using the guide I have written in the past.
Possibilities from commonspeak2
I have to confess. I never liked traditional brute-force method for subdomain enumeration. However, for some reason, commonspeak2 wordlist just works. To generate the possibilities, you can use this simple Python snippet:
scope = '<DOMAIN>'
wordlist = open('./commonspeak2.txt').read().split('\n')
for word in wordlist:
if not word.strip():
continue
print('{}.{}\n'.format(word.strip(), scope))
Run massdns
At this stage, you have a huge list of potential subdomains for your target. The potential means that they might exist and they might not. To verify that, you need to run an active DNS resolution. For that, massdns is the perfect tool. It is up to you how you approach the automation, I like to do it using Python:
#python3
import json
import subprocess
RESOLVERS_PATH = '/path/to/resolvers.txt'
def _exec_and_readlines(cmd, domains):
domains_str = bytes('\n'.join(domains), 'ascii')
proc = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.DEVNULL, stdin=subprocess.PIPE)
stdout, stderr = proc.communicate(input=domains_str)
return [j.decode('utf-8').strip() for j in stdout.splitlines() if j != b'\n']
def get_massdns(domains):
massdns_cmd = [
'massdns',
'-s', '15000',
'-t', 'A',
'-o', 'J',
'-r', RESOLVERS_PATH,
'--flush'
]
processed = []
for line in _exec_and_readlines(massdns_cmd, domains):
if not line:
continue
processed.append(json.loads(line.strip()))
return processed
print(get_massdns(['example.com', 'sub.example.com']))
Using -o J flag, massdns outputs the results in so-called ndjson format. We then need to enumerate through lines and treat each line as valid JSON which we can easily parse.
Altdns
This is an optional tool in my workflow which might bring more fruit to the table (read, more subdomains found). It works by creating permutations for existing domain names. For instance, given the domain name sub.example.com, altdns might provide possible permutations in the form of:
sub-dev.example.comsub01.example.com- ...
You get the point. The idea is to generate such possibilities and then resolve them at once to get the possible hits. It is basically a smart way of doing brute force. There is a very nice research paper written about this topic. The paper, however, introduces much more advanced research in this area. These topics are not yet implemented in altdns, I am currently working on the alternative tool, stay tuned!
To start the altdns for our purposes, we can run:
python altdns.py -i input_domains.txt -o ./output/path -w altdns/words.txt
Why do we run massdns twice? Altdns is a great tool for generating variations of domains names. It, however, returns a huge list of possibilities. Since the DNS resolutions take time, it is better to firstly resolve a smaller list of active domains after step #3. Altdns can then take only subdomains that are proven to be active, which results in a smaller list for resolution in step #6.
You might be wondering why I don't usually provide full scripts that are described in my articles. I think that for those of you who are willing to learn, it is better to try and glue these things together by yourself. Trust me, it is the best thing you can do if you are really serious about this stuff. You can always ask me questions on Twitter.
Until next time!

