
Recently, I was trying to extend my autonomous bug bounty finding engine. My first thought was to incorporate second order bugs into the subdomain takeover scanning process. In this post, I describe how I approached this challenge and how this process can be automated efficiently. There is a great article written by EdOverflow, but I feel there is a bit more to say about this topic.
Second order bugs happen when a website uses a "takeoverable domain" in the wrong place. Imagine a website that uses a Javascript file from the external domain. What happens when the domain is vulnerable to subdomain takeover? When the Javascript file is not available (e.g., the domain expired), the browser fails quietly. If this file is not extremely important to website functionality (e.g., live chat plugin), there is a possibility that website behavior remains unnoticed by administrators. We can register this domain and host our Javascript file, creating a very smooth XSS. It is a classic subdomain takeover example as I wrote about before. The diagram below illustrates this idea.
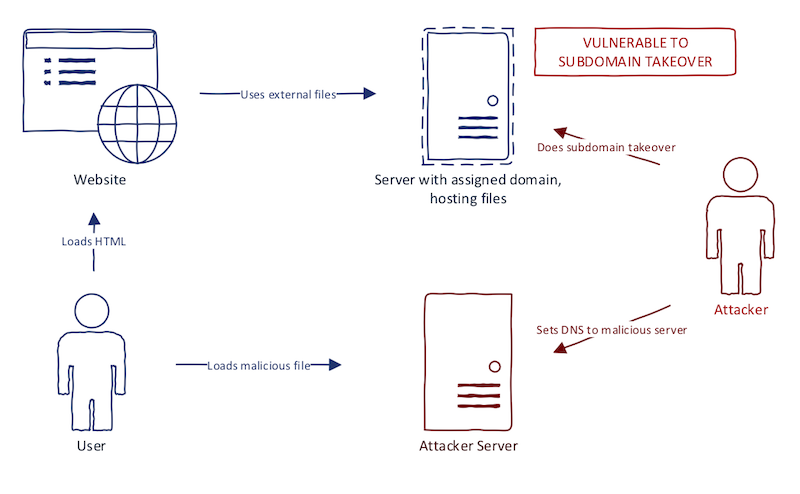
Why exactly is this called second-order bug? Well, first-order subdomain takeover bugs are just subdomains of the target program that is vulnerable to subdomain takeover. Second-order makes it clear that we are extending the "reach" of our scans to domains which can make a significant impact.
There is at least one open-source tool for this scans available: second-order. The problem is that it does not examine all the fields described in this post. It is, however, an excellent starting point. I just don't feel confident to extend its capabilities since it is written in Go.
Second order bugs are not limited to Javascript files. We can extend this idea to things like CORS. I recommend looking into this HackerOne report to see what I am talking about. The basic idea is this: We need to extract links and domains from places, where subdomain takeover would cause real trouble. What exactly are these places?
- script tags — impact: XSS
- a tags — impact: social engineering
- link tags — impact: clickjacking
- CORS response headers — impact: data exfiltration
Implementation
Now, let's look at how to implement this using Python. The high-level process looks like this:
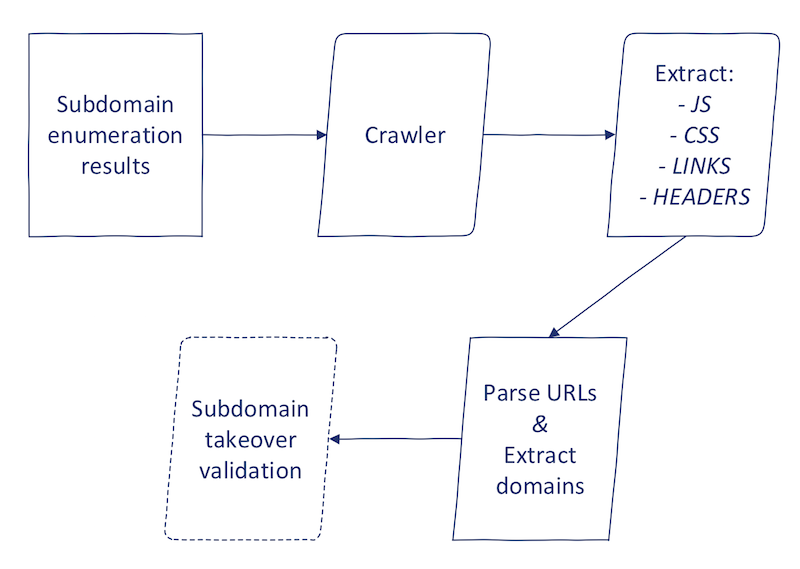
The first part consists of crawling in some shape or form. I will skip the technical details of this; it is up to you to decide what strategy to use. You may:
- Request only
/for every subdomain found - Do a limited crawl (e.g., BFS tree with height 1)
- Do a full crawl
The HTML files resulting from any of these crawls (well, the first option is not a crawl by any means) are fed into the extraction machine.
The extraction process takes several steps to complete. I used single functions to take care of each step. Let's look at it more deeply:
from bs4 import BeautifulSoup
def extract_javascript(domain, source_code):
'''
Extract and normalize external javascript files from HTML
'''
tree = BeautifulSoup(source_code, 'html.parser')
scripts = [normalize_url(domain, s.get('src')) for s in tree.find_all('script') if s.get('src')]
return list(set(scripts))
This piece of code extracts all links from script tags present in the HTML file. I used BeautifulSoup to do the HTML parsing for me. You might notice that there is a mysterious normalize_url function. I will explain it shortly.
def extract_links(domain, source_code):
'''
Extract and normalize links in HTML file
'''
tree = BeautifulSoup(source_code, 'html.parser')
hrefs = [normalize_url(domain, s.get('href')) for s in tree.find_all('a') if s.get('href')]
return list(set(hrefs))
def extract_styles(domain, source_code):
'''
Extract and normalize CSS in HTML file
'''
tree = BeautifulSoup(source_code, 'html.parser')
hrefs = [normalize_url(domain, s.get('href')) for s in tree.find_all('link') if s.get('href')]
return list(set(hrefs))
There should not be anything surprising; we are doing extraction analogously to script tags.
import requests
def extract_cors(url):
r = requests.get(url, timeout=5)
if not r.headers.get('Access-Control-Allow-Origin'):
return
cors = r.headers['Access-Control-Allow-Origin'].split(',')
if '*' in cors:
# Use your imagination here
return []
return cors
This is something different, but shouldn't be difficult to understand. There are, however different ways to express multiple origin domains. I assumed that ',' is the delimiter. You can do research and make it more robust; there might be different ways to provide multiple origin domains (let me know if you find it).
def normalize_url(domain, src):
'''
(Try to) Normalize URL to its absolute form
'''
src = src.strip()
src = src.rstrip('/')
# Protocol relative URL
if src.startswith('//'):
return 'http:{}'.format(src)
# Relative URL with /
if src.startswith('/'):
return 'http://{}{}'.format(domain, src)
# Relative URL with ?
if src.startswith('?'):
return 'http://{}/{}'.format(domain, src)
# Relative URL with ./
if src.startswith('./'):
return 'http://{}{}'.format(domain, src[1:])
# Absolute URL
if src.startswith('https://') or src.startswith('http://'):
return src
# Else let's hope it is relative URL
return 'http://{}/{}'.format(domain, src)
This function tries to normalize the given URL into its absolute forms. As you may know, arguments to src or href HTML parameter can include relative addresses as well. The normalize_url function returns an URL in its absolute form, so we can easily extract the domain and other parts from it.
We only need to extract the domain name from our absolute URL. This is a pretty straightforward task in Python:
from urllib.parse import urlparse
def extract_domain(url):
'''Extracts domain name from given URL'''
return urlparse(url).netloc
The extracted domains are now ready to be forwarded into a subdomain takeover verification engine. I talked about creating one here. This process should be enough to identify higher-order subdomain takeover bugs. You can view the full snippet on GitHub.
These bugs are very rare. I came across only one in the past. However, since the process can be easily automated, there is no reason not to include it in your automation workflow. You might get lucky and get one in the future. Happy hunting.
Check out my other posts about subdomain takeovers:
- Subdomain Takeover: Thoughts on Risks
- Subdomain Takeover: Basics
- Subdomain Takeover: Proof Creation for Bug Bounties
- Subdomain Takeover: Finding Candidates
Until next time!

